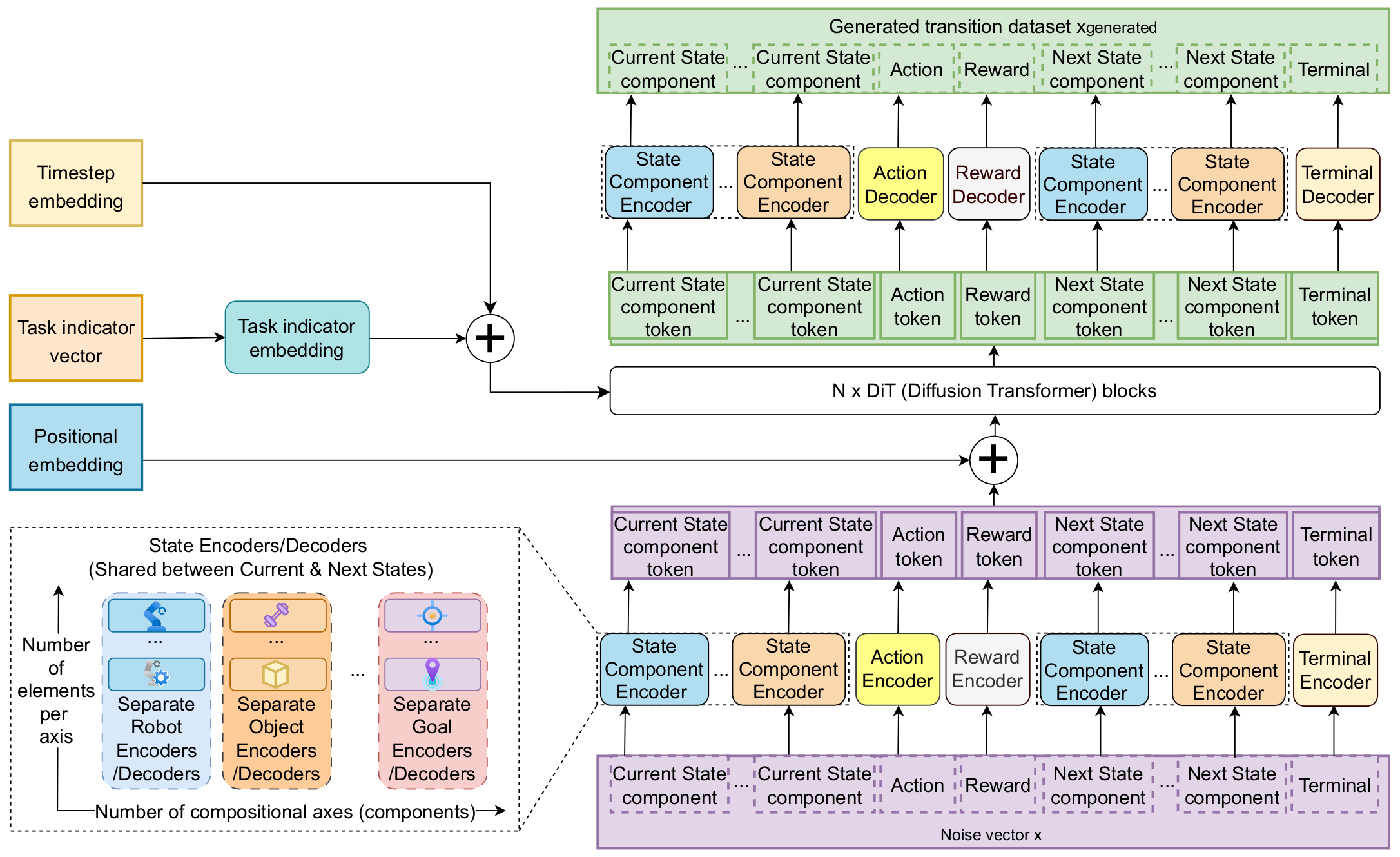
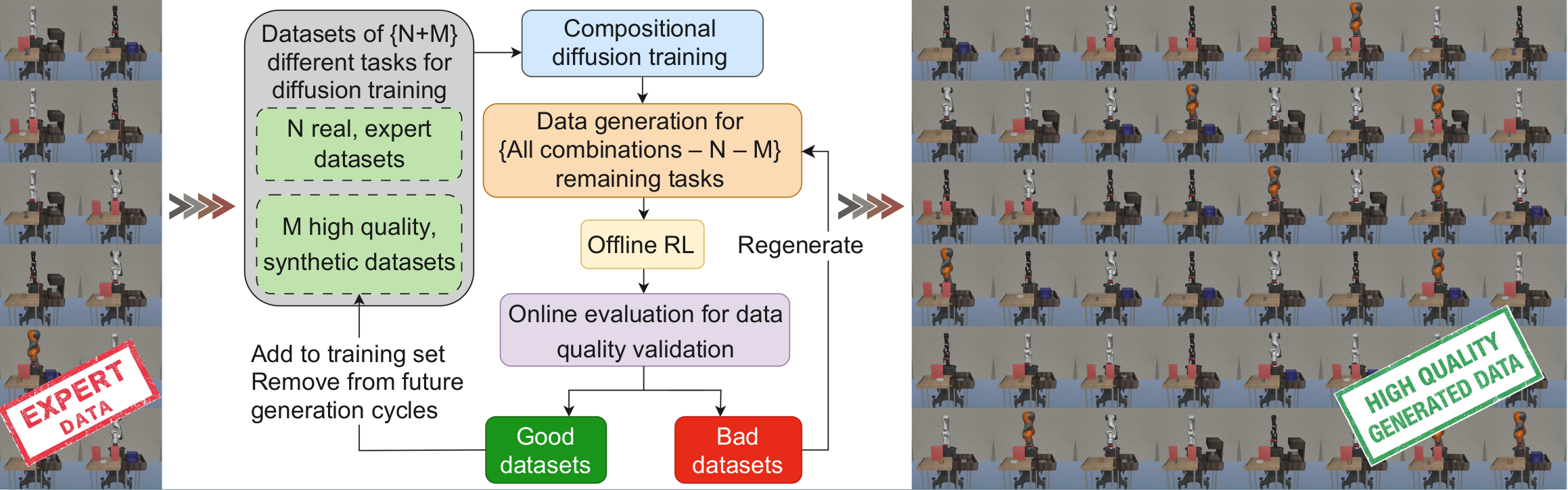
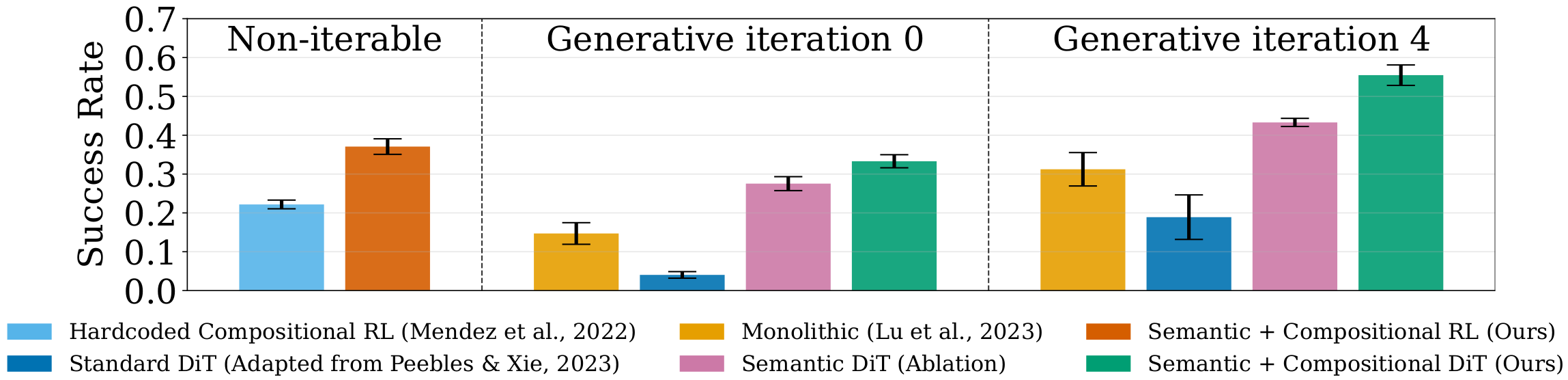
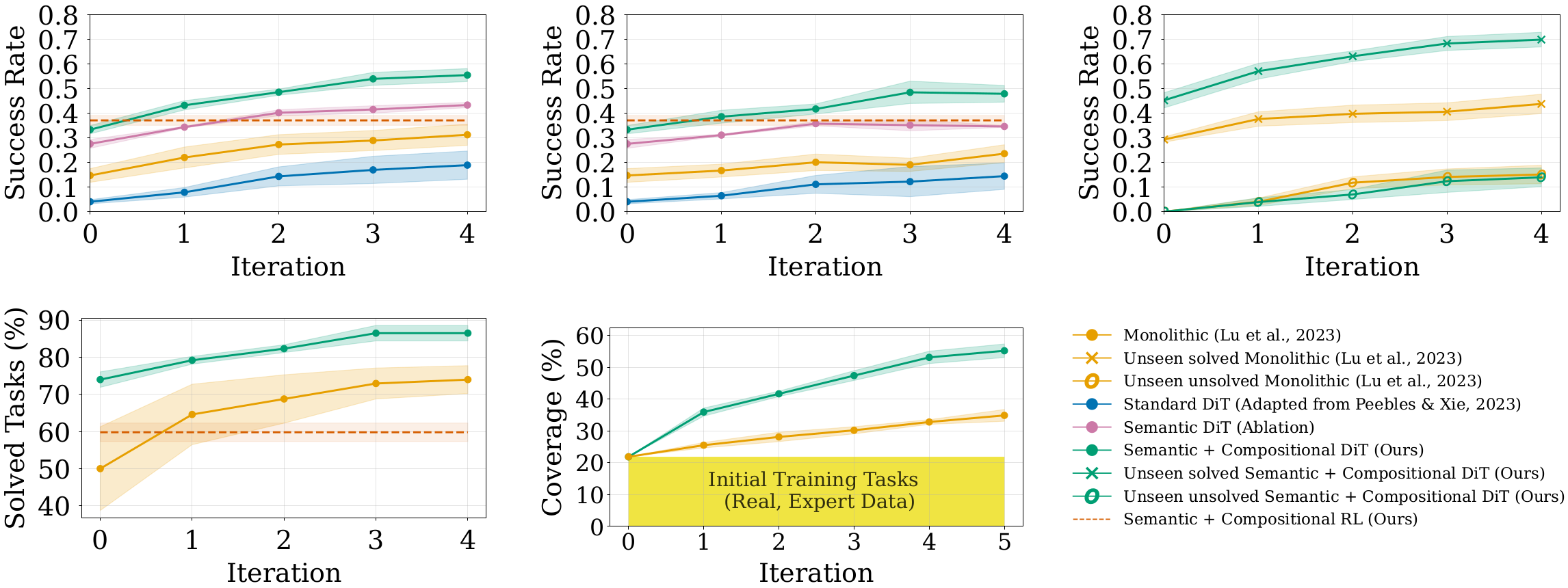
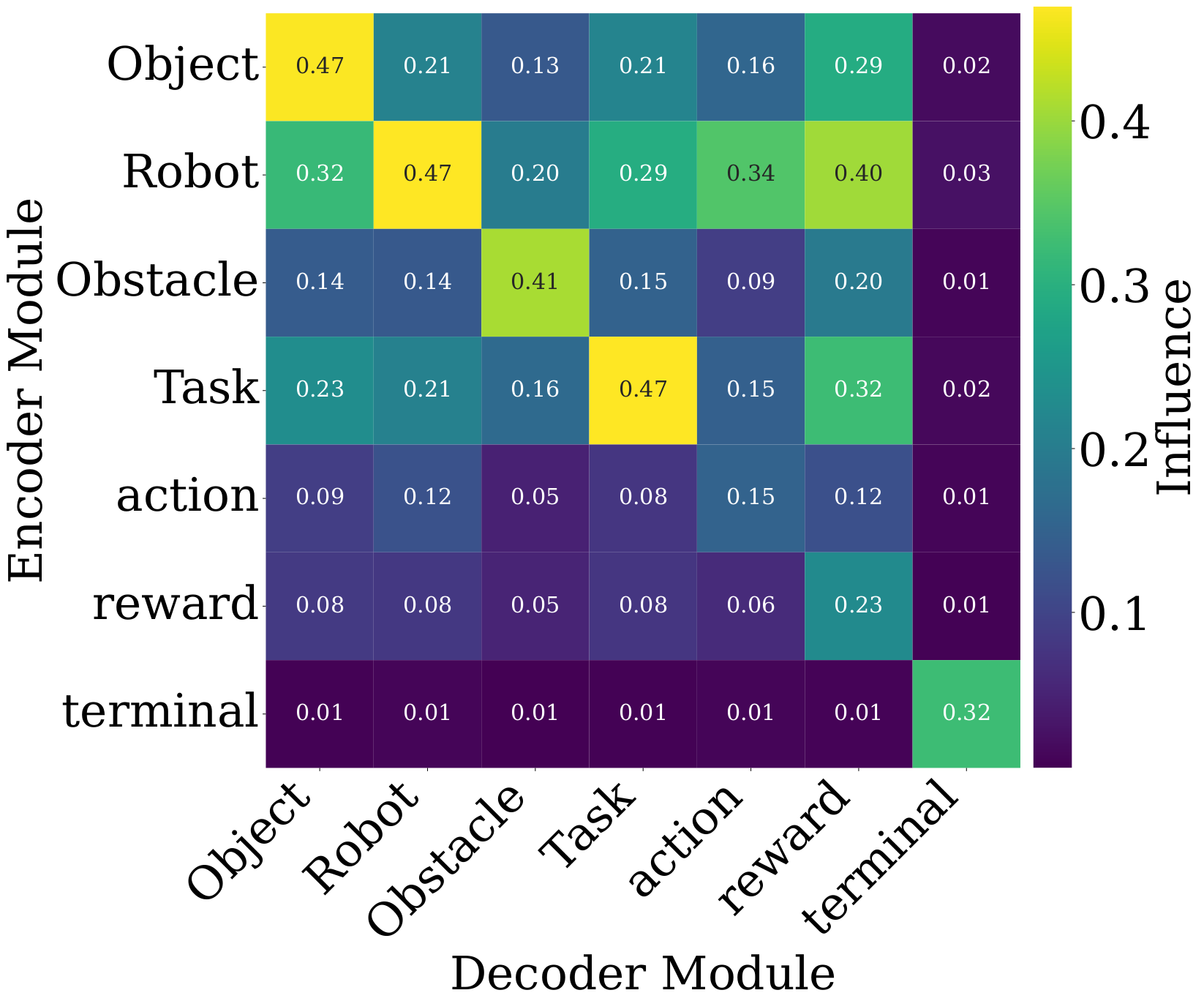
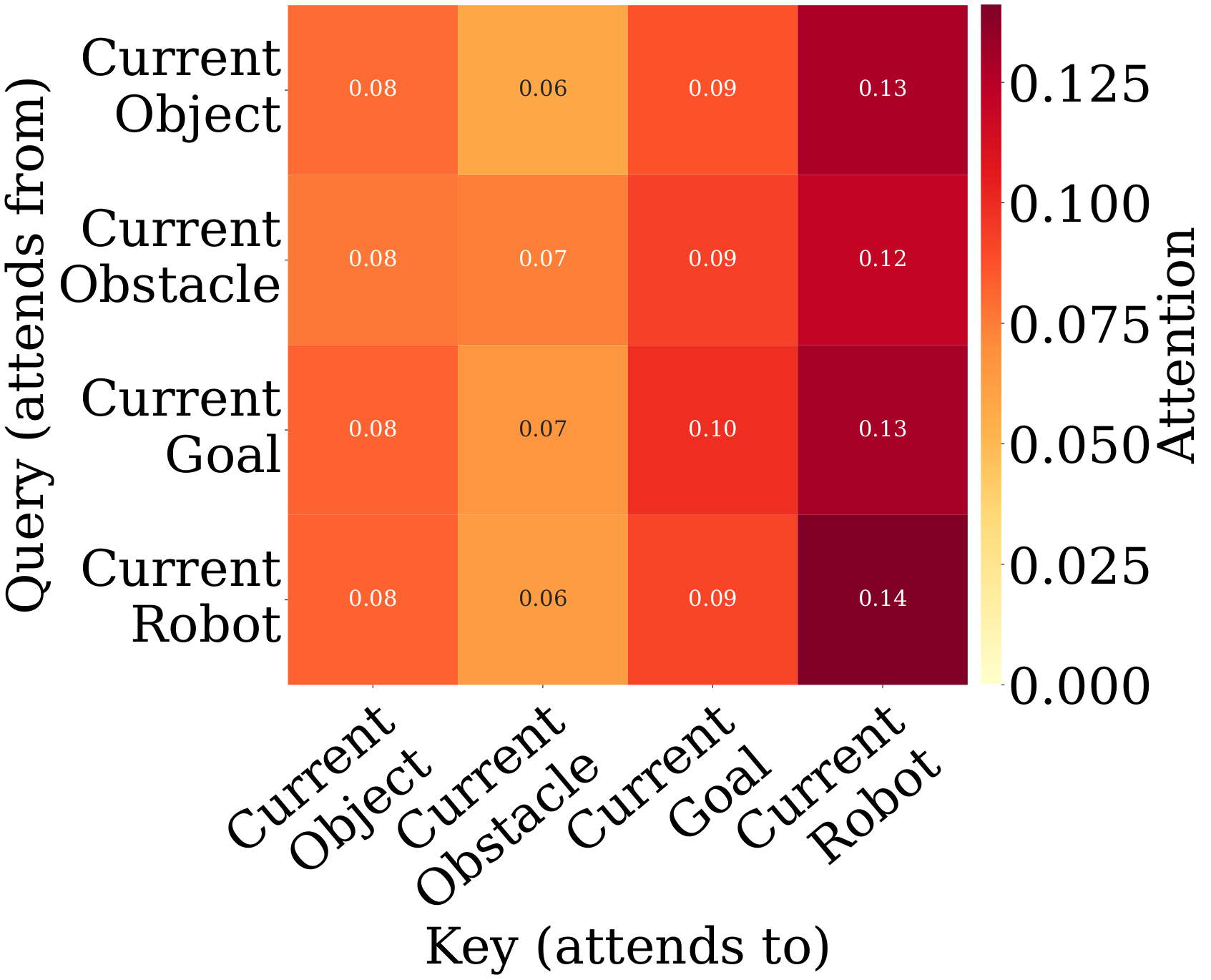
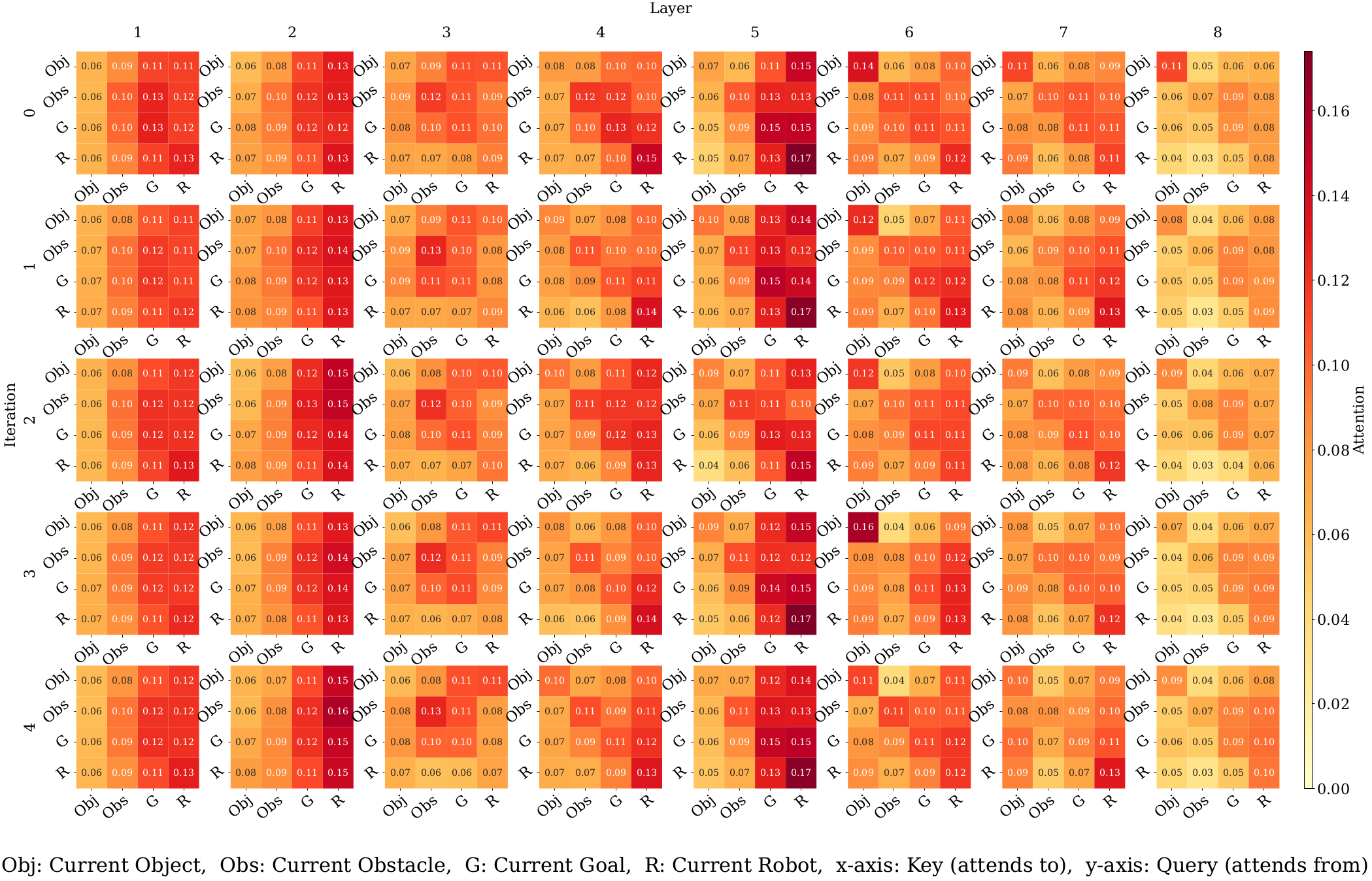
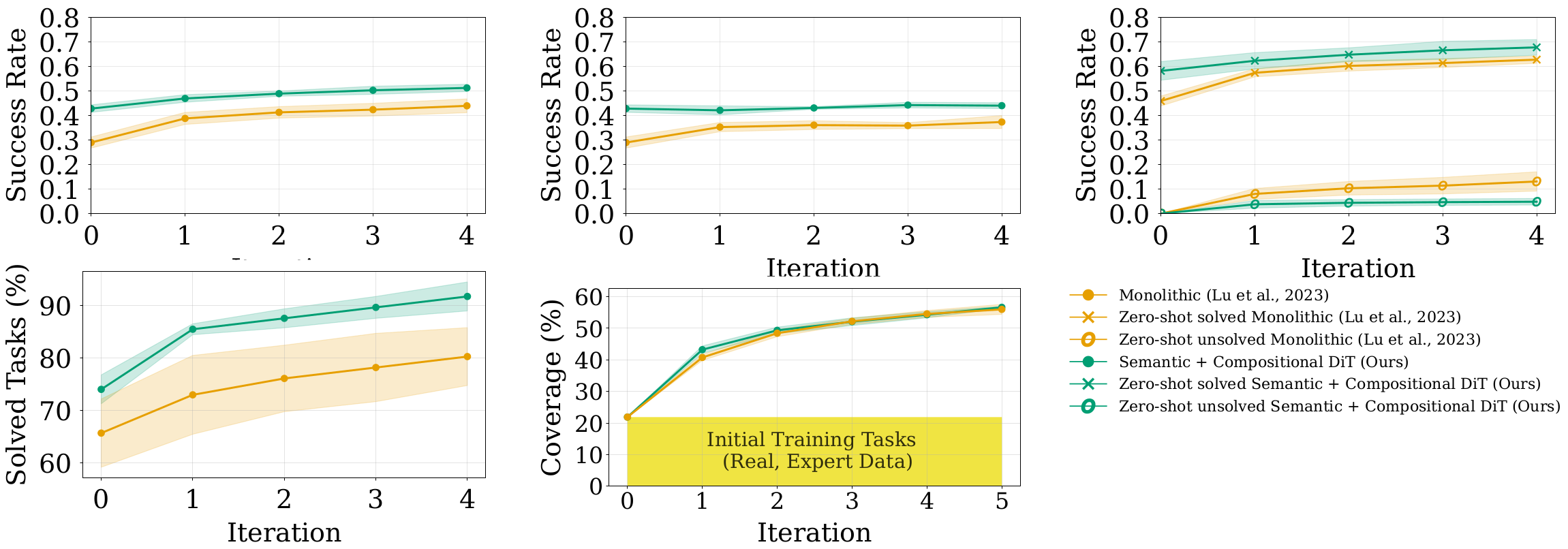
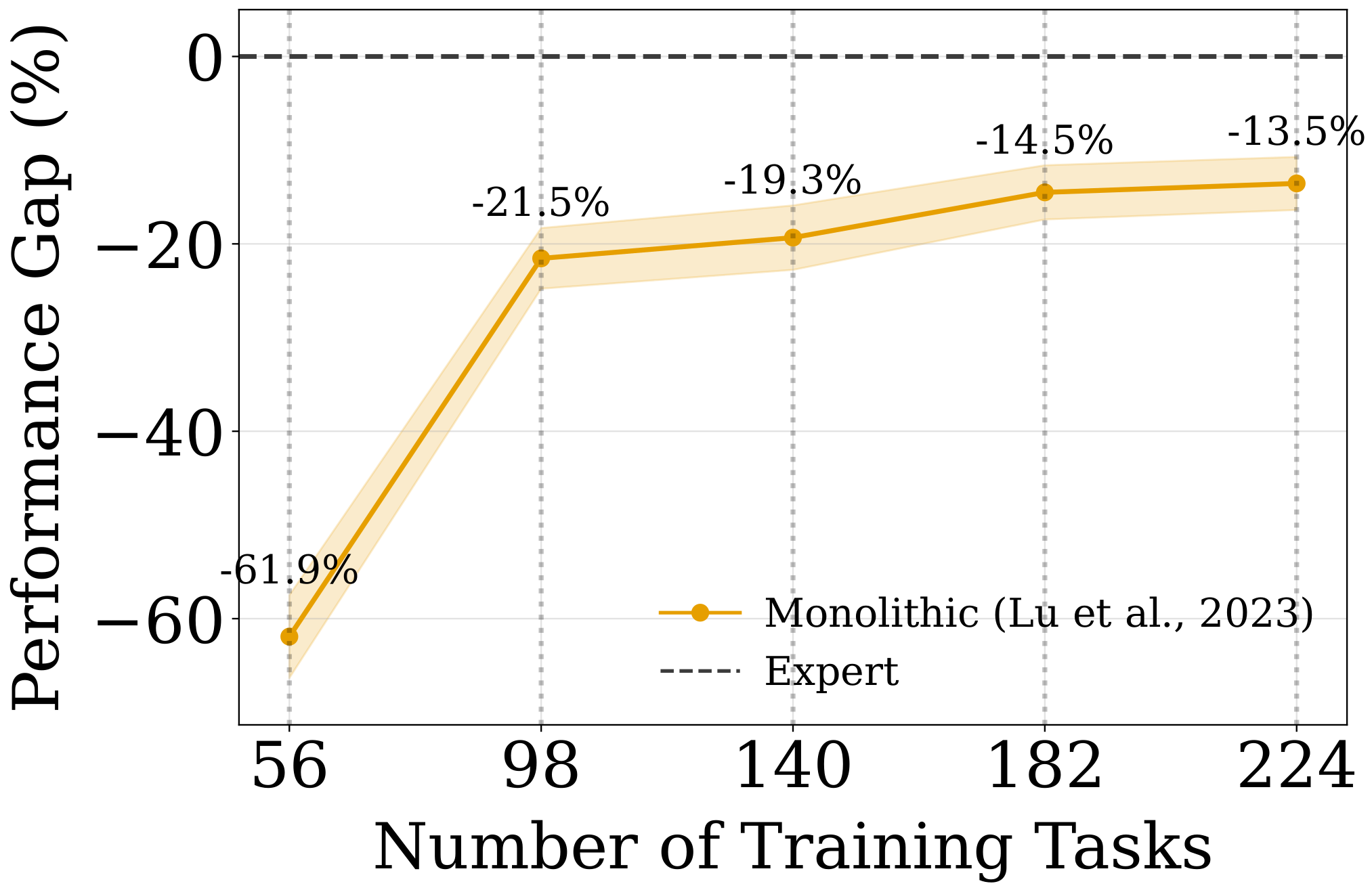
Setting
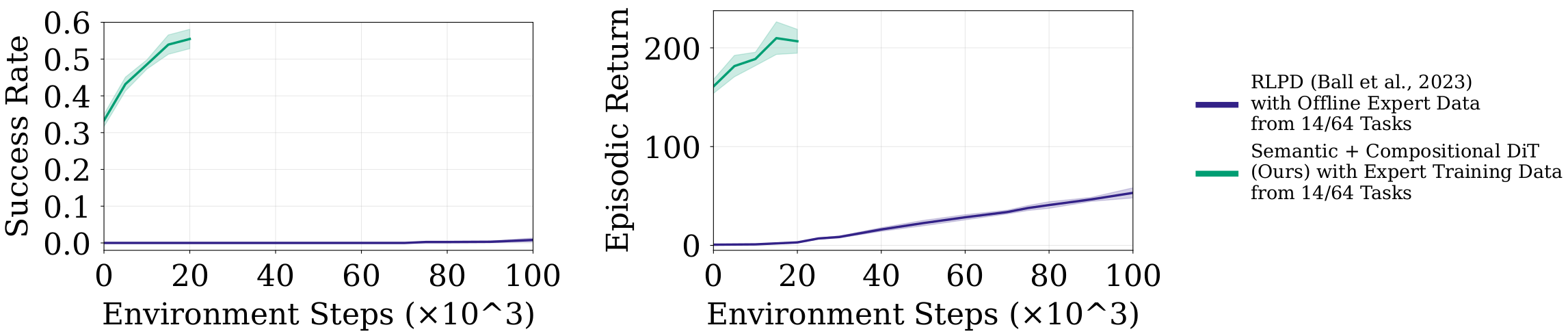
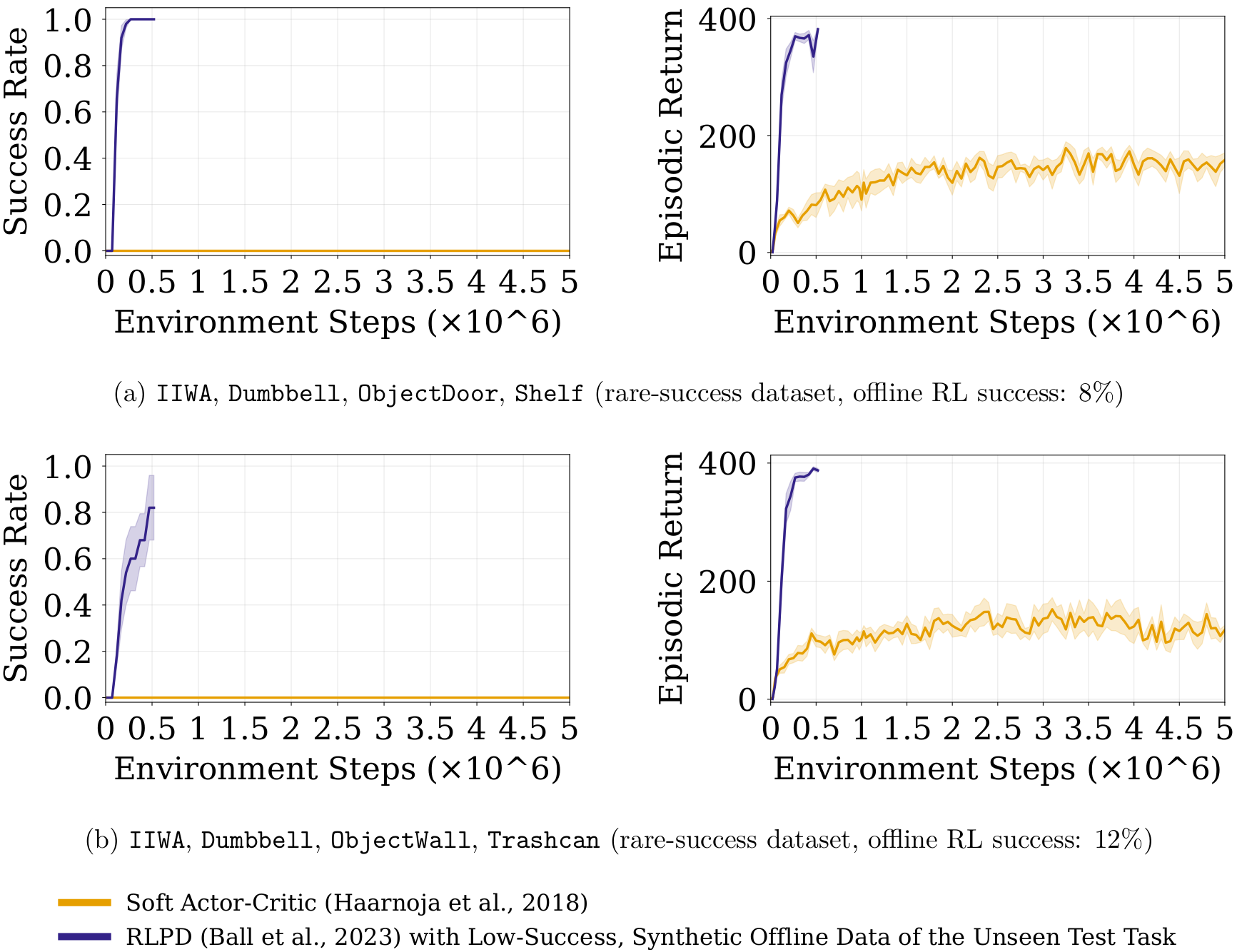
To ground this idea, we use CompoSuite (Mendez et al., 2022), which provides 4×4×4×4 = 256 tasks by composing one element from each axis: robot, object, obstacle, and objective. Our main experiments study a 14-task training regime where the robot is fixed to IIWA (the remaining three axes vary), providing access to 4×4×4 = 64 possible task combinations. We evaluate our approach on 32 held-out tasks that are not used during training.

IIWA, Box, None, PickPlace
Jaco, Dumbbell, ObjectWall, Push
Panda, Plate, ObjectDoor, Shelf
Kinova3, Hollowbox, GoalWall, TrashcanFour example CompoSuite tasks, each defined by selecting one element from each axis.